ファイルシステム(ext2/ext3/ext4)の基礎まとめ
ext2

スーパーブロックには全体のi-node数など、グループデスクリプタにはそのブロックグループのi-node数など、i-nodeにはファイルのメタデータとデータブロックのアドレスなど、が記録されている
- スーパーブロックはバックアップされており、
mkfs.ext2 -nでバックアップされたブロックを確認することができ、mkfs.ext2 -bでそのブロックを指定することで復旧できる
- スーパーブロックはバックアップされており、
間接ブロック参照 - ext2のi-nodeにはデータが保存されているブロック番号を格納するサイズ15のテーブルがあり、そのうち#0〜#11は直接ブロック参照(ブロック番号を格納する)、#12は1段間接ブロック参照(ブロック番号を格納したテーブルを参照する)、#13は2段間接ブロック参照(ブロック番号を格納したテーブルを参照するテーブルを参照)、#14は3段間接ブロック参照、に使用される
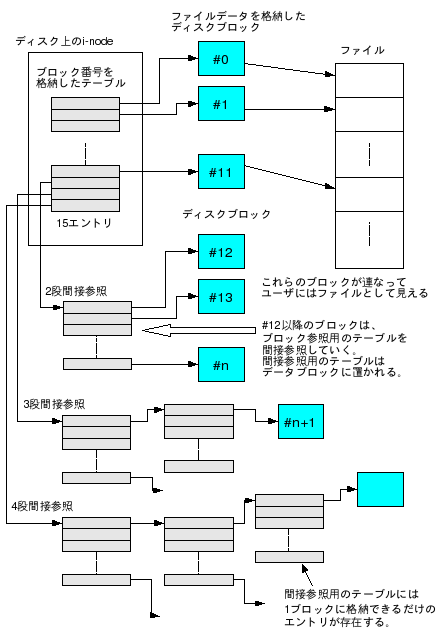
間接ブロック参照によって1ファイル4TBまでブロックを参照できるが、i-nodeのメタデータにあるブロック数が2TB(ブロックサイズが4KBの場合)までしか管理できないので、そちらが1ファイルサイズの限界を決めている
大きいサイズのファイルになると間接参照が多くなるため、書き込みや読み込みの性能が悪くなる
ext3
ジャーナリング
- データの更新処理を、不可分(アトミック)な一つのトランザクションに集約して記録することで、ファイルシステムの整合性を維持するための仕組み
- たとえファイルを削除するという単純なトランザクションの中でも、スーパーブロックやファイルのメタデータに対する様々なステップ処理が存在するため、その途中で不正なシャットダウン(アンマウント)が発生し、一部のステップ処理のみが実行される状態になるとメタデータの整合性が崩れる
- ジャーナルログがあれば、不正なアンマウントが発生してそのパーティションが
cleanな状態でなくなっても、メタデータと実データとの不整合を復旧するだけでよい - ただしext3であっても、何らかの不正な書き込みが発生してメタデータの整合性が壊れると、fsckによるステップ処理単位での復旧が必要になるし、fsckを実施していない期間がある一定期間を超えるとパーティション全体の整合性を確認することになる
O+P Insights: Improving Ext3 performance with an external journal on an SSD Disk

- 作者: 高橋浩和,小田逸郎,山幡為佐久
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2006/11/18
- メディア: 単行本
- 購入: 14人 クリック: 197回
- この商品を含むブログ (119件) を見る
fsck
- メタデータの矛盾を取り除くコマンド。壊れたデータを復旧するわけではなく、メタデータの整合性が取れるように壊れた部分を排除する。
- ファイルシステムには定期的にfsckを実行するオプションがある。ジャーナルログを採用しているファイルシステムであっても、マウントを実行した回数や前回fsck実行からの期間、によってサーバ起動時にfsckが発動してパーティション全体を走査することによる起動遅延が発生することがある。
$ sudo tune2fs -l /dev/sda1 | egrep -i "mount count|check" Mount count: 16 Maximum mount count: -1 Last checked: Sun Jun 19 00:06:19 2016 Check interval: 0 (<none>)
- fsckのチェックによってファイルシステムの整合性を保つためにディレクトリやi-nodeの内容が破棄されることで、参照不可能になったデータブロックの内容は
/lost+foundディレクトリに#とi-node番号をファイル名として退避される。
kjournald
- トランザクションを、定期的にディスク上のジャーナルログ領域に書き込む(コミットする)デーモン
- kjournaldの書き込み間隔はデフォルトで5秒で、この間隔は信頼性と性能(データの永続化とDisk I/Oの回避)のトレードオフとなる
ジャーナルモード
- ジャーナルモードはマウントオプションとして
data=journalなどとして指定する
journal
- メタデータと実データのトランザクションをコミットしたのち、メタデータと実データをディスク上のデータ領域に書き込む
- 完全にデータを冗長化することができるが、書き込み性能は悪い
- ジャーナルログとデータ領域に不整合が発生することがない
ordered
- 実データが書き込まれたのち、メタデータのトランザクションをコミットする
- つまり、実データの書き込み順序と、トランザクションへのコミット順序が、常に一貫性を保つ(シーケンシャルに実行される)ことを保証する
- 実データがディスク上のデータ領域に書き込まれる前に不正なアンマウントが発生すると...
- ジャーナルログから、ディスク上のデータ領域のメタデータを復旧する
- 新しい実データが(バッファには書き込まれているものの)ディスク上のデータ領域に書き込まれていない場合は、実データは復旧できない
- 新しい実データの復旧はできないが、ジャーナルログによるメタデータの復旧は可能になる
writeback
- 実データの書き込み順序と、トランザクションへのコミット順序が、一貫性を保てない
- 実データがデータ領域に書き込まれる前に不正なアンマウントが発生すると...
- ジャーナルログはシーケンシャルに書き込まれたものであることが保証されていないため、メタデータの復旧が正しく行われないことがある
- 書き込み性能は最も良いが、メタデータの復旧がうまくいかない場合があることを許容する動作になる
MySQL(InnoDB)との関連について一言
WAL / Double Write
- WAL (Write Ahead Log) は、トランザクションがコミットされたときに、トランザクションの内容をディスク上のログ領域に書き込む(更新データはバッファ上に残っている)
- Double Writeは、バッファからディスクへフラッシュされたときに、ディスク上のデータ領域に書き込む前に、ダブルライトバッファ領域に書き込む(更新データのコピーを保持することができる)
- これらの領域はシーケンシャルに書き込まれていくので、ディスク上のシーク時間が短く、I/Oに必要な時間が短い(Double Writeといっても書き込み時間が二倍になるわけではない)
ext4
遅延確保 - ext3まではバッファ書き込み時にディスク上のブロック割り当てを行うが、これをバッファ書き込み時からディスク書き込み時にまで遅延することで、複数の書き込みをまとめてブロック割り当てを行うことができるため、連続したブロックを割り当てやすくなりフラグメンテーションを起こりにくくする
エクステントの導入 - 大きなファイルに対して、複数のブロックの格納場所を全て保持する(かつ、多段参照のオーバーヘッドがある)と非効率なため、隣接するブロックに対してその格納場所を配列として保持することにより効率化する(先頭ブロックの格納場所と連続ブロック数(オフセット)、を組み合わせて複数保持する)
- 一つのi-nodeに格納できるエクステントは限りがあるので、Extent-IndexをB-treeとして保持することで検索効率を上げる
https://www.usenix.org/legacy/event/lsf07/tech/cao_m.pdf
- ナノ秒単位のタイムスタンプ
# ext4 $ mount | grep " / " /dev/mapper/fedora-root on / type ext4 (rw,relatime,seclabel,data=ordered) $ stat /etc/fstab File: ‘/etc/fstab’ Size: 465 Blocks: 8 IO Block: 4096 regular file Device: fd01h/64769d Inode: 130747 Links: 1 Access: (0664/-rw-rw-r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: system_u:object_r:etc_t:s0 Access: 2017-02-14 09:24:21.453460379 +0900 Modify: 2014-03-01 18:43:24.267325166 +0900 Change: 2014-03-01 18:43:24.267325166 +0900 Birth: -
# ext3
$ dd if=/dev/zero of=ext3img bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 0.386865 s, 271 MB/s
$ mkfs.ext3 -F ext3img
mke2fs 1.42.12 (29-Aug-2014)
Discarding device blocks: done
Creating filesystem with 102400 1k blocks and 25688 inodes
Filesystem UUID: 235bf453-34b4-430e-b508-4279dbc61c6c
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Allocating group tables: done
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
$ sudo mkdir /mount
$ sudo mount -t ext3 -o loop ext3img /mount/
$ mount | grep ext3
/home/nishidy/ext3img on /mount type ext3 (rw,relatime,seclabel,data=ordered)
$ sudo touch /mount/file
$ sudo vim /mount/file
$ stat /mount/file
File: ‘/mount/file’
Size: 12 Blocks: 4 IO Block: 1024 regular file
Device: 700h/1792d Inode: 14 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:file_t:s0
Access: 2017-02-14 09:31:39.000000000 +0900
Modify: 2017-02-14 09:31:25.000000000 +0900
Change: 2017-02-14 09:31:25.000000000 +0900
Birth: -
チェックサムの導入 - ジャーナルログにチェックサムが追加されて、ジャーナルログに対するチェックサムチェックが可能になり、信頼性が向上する
H-Tree - ext2/ext3ではディレクリ構造が連結リストにより管理されていたが、連結リストでは探索にO(n)の時間がかかるため、B-Treeの改良版であるH-Treeが採用されており、これにより探索時間が短縮される*1
- 動的なi-node確保 - ...
B-Tree

- Balanced Tree(平衡木の一つ)
- 検索における計算量
- 木に含まれる全てのキーの数をn、ノードが持つ子の最大数をm(ノードが持つキーの最大数をm-1)とする
- ノードが持つ子の平均数は m/2 になり、よって木の深さは
となる
- ノードのキー探索回数は、mが大きいときにはBinary Searchによってlog mとなる(キーはソート済み)
- よって計算時間は log m *
e.g.
30 50 70 | 10 20 | 40 | 60 | 80 90 |
B+-Tree
e.g.
30 50 70 | 10 20 | 30 40 | 50 60 | 70 80 90 |
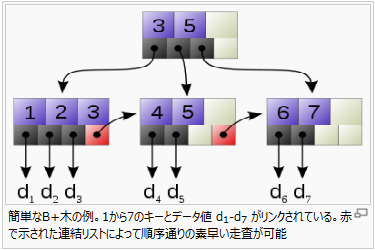
Oracle の B*Tree インデックスの内部構造についてお勉強中(その1) - drk7jp
B*-Tree
- B+-Treeを拡張して、ノードの持つキー数をなるべく多く保つ(as dense as possible)ことで、メモリ利用効率や検索速度が向上
- 最大数のキーを保持しているノードに挿入する場合、(B+-Treeのように)即座にノードを分割するのではなく、隣のノードに空きがある場合は、親ノードを介した回転を伴って、隣のノードにキーを移動させる
- 隣のノードも最大数のキーを保持している場合、二つのノードを三つのノードに分割する
")
- 作者: ドナルド・E.クヌース,Donald E. Knuth,有澤誠,和田英一
- 出版社/メーカー: アスキー
- 発売日: 2006/04/01
- メディア: 単行本
- 購入: 2人 クリック: 74回
- この商品を含むブログ (22件) を見る
XFS
- アロケーショングループ
Btrfs
- コピーオンライト(CoW)
- データ更新時にスナップショットを作成することで、障害時の実データのロールバックが可能に
- データコピー時には実体への参照のみを作成することで、高速な処理が可能に(データ更新時に実体を作成)
- 透過圧縮
- ディスクに書き込む・読み込む際にファイルシステムのサポートによってデータを圧縮・解凍する(LZO、ZLIB)
- 圧縮・解凍のためにCPU使用率が上がるが、書き込む量を減らすことで、ディスクスペースの利用効率だけでなく、ディスクI/Oの効率を上げる効果がある
- LVMのようなボリューム管理機能
...
www.slideshare.net
ハードリンクとシンボリックリンクの違い
- ハードリンクは、オリジナルファイルと同じi-node番号を持つファイル。i-node番号が同じファイルのため、オリジナルファイルをどのパスに移動しても、ハードリンクはパスに関係無くオリジナルファイルへ追従することができる。ただし、ハードリンクはオリジナルファイルと別のファイルシステム上には作成できない。i-node番号体系が異なるためである。
- i-nodeには参照カウントがあり、ハードリンクが作成されるとオリジナルファイルの参照カウントがインクリメントされる。ハードリンクが削除されると参照カウントはデクリメントされる。参照カウントが0になった時点で実体のブロックは解放可能となる。
シンボリックリンクの実体はオリジナルファイルへのパスである。従って、シンボリックリンクはハードリンクと別のファイルシステム上にも作成できる。ただし、オリジナルファイルを移動したり削除したことに気が付かない。
ディレクトリエントリは、ファイル名とi-node番号を対としたリストを持つ。従って、i-nodeにファイル名の情報は無い。"."は自分自身のディレクトリのi-node番号を指すため、ディレクトリ作成時にそのディレクトリの参照カウントは2となる。".."は親ディレクトリへのi-node番号を指すため階層構造をルート方向へ追跡することができる。