Linuxにおける各種メモリについて
Linuxで扱う様々な種類や単位のメモリについてまとめておく。また、メモリというリソースに関する制御や管理について考察する。
ulimit
$ ulimit -a | egrep "memory|stack" max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited stack size (kbytes, -s) 8192 virtual memory (kbytes, -v) unlimited
- max locked memory -
mlockシステムコールを使うことにより、メモリの内容がディスク上にスワップされないようにする(=Lockする)ことができる。その最大容量。 - max memory size - 静的(スタック領域)や動的(ヒープ領域)に確保するメモリの最大容量。
- virtual memory - スワップされたプロセスが使用するディスク上の仮想メモリ空間の最大容量。
- stack size - 静的(スタック領域)に確保するメモリの最大容量。
ulimitの機能
- シェル組み込みの機能で、ユーザ毎にCPUやメモリ、ファイル、PIPEなどのリソースの使用量に制限を設ける。
- ソフトリミットはハードリミットを超えない範囲で設定が可能で、ハードリミットを上げることができるのはrootのみ。
- ulimitの制御は、setrlimit/getrlimitシステムコールを使って行われる。
$ strace bash -c "ulimit -S -s 65535" 2>&1 | grep -i rlimit
getrlimit(RLIMIT_NPROC, {rlim_cur=1024, rlim_max=3897}) = 0
getrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
getrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
setrlimit(RLIMIT_STACK, {rlim_cur=65535*1024, rlim_max=RLIM64_INFINITY}) = 0
$ strace bash -c "ulimit -H -s 819200" 2>&1 | grep -i rlimit
getrlimit(RLIMIT_NPROC, {rlim_cur=1024, rlim_max=3897}) = 0
getrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
getrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
setrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=819200*1024}) = 0
- なお、ディスク(パーティション)の使用量制限に関してはulimitではなくquotaで行う。
quota
- ユーザ単位・グループ単位でディスク(パーティション)の使用量に制限を設ける。
- mountオプションとしてusrquota・grpquotaを指定する必要がある。
- ソフトリミットは猶予期間内であれば超えることができるが、猶予期間を超えるとソフトリミットがハードリミットとなる。
- ハードリミットは超えることができない。
- quotaの管理は、パーティションのトップディレクトリに置かれるaquota.user, aquota.groupファイル上で行われる。
ps / pmap / time*1
$ ps aux | head -n1
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
$ pmap -X $(pidof bash) | head -n2
2571: pmap -X 2571 2073
Address Perm Offset Device Inode Size Rss Pss Referenced Anonymous Swap Locked Mapping
$ /usr/bin/time -apv ls 2>&1 | grep resident
Maximum resident set size (kbytes): 2428
Average resident set size (kbytes): 0
- VSS/VSZ (Virtual Set Size) - プロセスの仮想メモリ全体のサイズ。実際には使用していない領域を含んでいる。
- RSS (Resident Set Size) - プロセスが仮想メモリの中で、実際に使用しているメモリのサイズ。共有ライブラリのメモリを含むため、各プロセスで重複してカウントされている。また、スワップアウトされているメモリは含まれない。
PSS (Proportional Set Size) - プロセスが実際に使用しているメモリのサイズ。共有ライブラリのメモリを含むが、そのライブラリを使用しているプロセス数で割っているため、RSSの問題点は解決している。
(例)dhclientとcupsdはlibcryptoを共有ライブラリとして利用しており、それぞれのプロセスのRSSとしてカウントされている。
$ ldd /sbin/dhclient | grep libcrypto
libcrypto.so.10 => /usr/lib64/libcrypto.so.10 (0x00007f62d75f7000)
$ ldd /usr/sbin/cupsd | grep libcrypto
libcrypto.so.10 => /usr/lib64/libcrypto.so.10 (0x00007fd442cef000)
$ ps -FC dhclient
UID PID PPID C SZ RSS PSR STIME TTY TIME CMD
root 2394 842 0 25553 19040 0 23:27 ? 00:00:00 /sbin/dhclient -d -sf /usr/libexec/nm-dhcp-helper -pf /var/run/dhclient-p2p1.pid -lf /var/lib/
$ ps -FC cupsd
UID PID PPID C SZ RSS PSR STIME TTY TIME CMD
root 1709 1 0 47262 2044 0 23:11 ? 00:00:00 /usr/sbin/cupsd -f
$ man ps
...
rss RSS resident set size, the non-swapped physical
memory that a task has used (inkiloBytes).
(alias rssize, rsz).
...
pmapのRSSとSizeは、実際にメモリに読み込まれているかどうかの違いがある。この違いは、デマンドページングによりページフォルトが発生するまで実際のメモリへの読み込みを遅延する、ことによって現れる。それによって、例えば共有ライブラリの中の実際に使用する関数のみをメモリに読み込んで実行することができる。Sizeは実際には読み込まれておらず、論理アドレスに割り当てただけの部分もカウントしている。
デマンドページングは
malloc発行時にも効果を発揮する。mallocを発行すると論理アドレス上ではメモリを割り当てたことになるが、物理メモリ上ではまだメモリ領域は確保されず、実際にメモリに書き込んだ際、初めて物理メモリ上でメモリ領域が確保される。この機構により実際の物理メモリ容量よりも大きいメモリをmallocにより割り当てることができ、これをオーバーコミットと呼ぶ。ただし、実際に物理メモリ以上の領域に書き込もうとすると、メモリ不足の例外が発生するか、OOM Killerにより停止されるだろう。オーバーコミットの容量はsysctlである程度制御が可能である。
/proc/meminfo
$ cat /proc/meminfo | egrep -i "active|dirty|claim|mem|slab" MemTotal: 1017448 kB MemFree: 97304 kB MemAvailable: 316264 kB Active: 317736 kB Inactive: 371132 kB Active(anon): 209564 kB Inactive(anon): 244268 kB Active(file): 108172 kB Inactive(file): 126864 kB Dirty: 324 kB Shmem: 3444 kB Slab: 192720 kB SReclaimable: 152860 kB SUnreclaim: 39860 kB
- anon(Anomymous) - プロセスが確保したメモリ。ディスクに退避(スワップ)されることがある。
- file(File-backed) - OSがディスクキャッシュとして確保したメモリ。(Dirtyなもの以外は)もともとディスク上に存在するデータ。
Shmem - tmpfsとして使用されているメモリ。tmpfsはメモリ上にのみ存在するが、スワップの対象となりディスクに書き出される。
Active/Inactive - LRU的に、最近使用されたメモリか、利用されていないメモリか。
Dirty - ディスクに書き込まれていないFile-backedなバッファ。syncでディスクに書き込むと0になり、Cleanなバッファとなる。Cleanなバッファは、
echo 1 > /proc/sys/vm/drop_cachesで解放される。
$ cat /proc/meminfo | grep Dirty Dirty: 1032 kB $ sync $ cat /proc/meminfo | grep Dirty Dirty: 0 kB
Slab - SReclaimable + SUnreclaim
- SReclaimable - 解放可能なSlab。
echo 2 > /proc/sys/vm/drop_cachesで解放される。 - SUnreclaim - 解放不可能なSlab。
- SReclaimable - 解放可能なSlab。
echo 2 > /proc/sys/vm/drop_cachesの直後でもSReclaimableは0にならないが、slabtopで確認するとdentryやinodeがSlabを使用しているのが分かる。バックグラウンドプロセスやカーネルの処理が動いているため、すぐにSlabの割り当てが行われているのだろう。
$ cat /proc/meminfo | egrep -i "slab|claim" Slab: 210504 kB SReclaimable: 170240 kB SUnreclaim: 40264 kB $ echo 2 > /proc/sys/vm/drop_caches $ cat /proc/meminfo | egrep -i "slab|claim" Slab: 79436 kB SReclaimable: 45460 kB SUnreclaim: 33976 kB $ slabtop -o -sc | head -n 12 Active / Total Objects (% used) : 579600 / 661586 (87.6%) Active / Total Slabs (% used) : 11754 / 11754 (100.0%) Active / Total Caches (% used) : 74 / 100 (74.0%) Active / Total Size (% used) : 51588.87K / 78695.04K (65.6%) Minimum / Average / Maximum Object : 0.01K / 0.12K / 8.00K OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME 29368 8839 30% 0.99K 1894 16 30304K ext4_inode_cache 9674 9378 96% 0.55K 691 14 5528K inode_cache 63189 20416 32% 0.08K 1239 51 4956K Acpi-State 21210 12372 58% 0.19K 1010 21 4040K dentry 118528 118528 100% 0.03K 926 128 3704K kmalloc-32 $ slabtop --help ... The following are valid sort criteria: c: sort by cache size ...
$ sudo cat /proc/vmallocinfo | grep ioremap
0xffffc90000000000-0xffffc90000004000 16384 acpi_os_map_iomem+0xf7/0x150 phys=3fff0000 ioremap
0xffffc900001f8000-0xffffc900001fb000 12288 pci_iomap+0x55/0xb0 phys=f0806000 ioremap
0xffffc900001fc000-0xffffc900001fe000 8192 usb_hcd_pci_probe+0x14d/0x550 phys=f0804000 ioremap
0xffffc90000280000-0xffffc900002a1000 135168 pci_ioremap_bar+0x46/0x80 phys=f0000000 ioremap
0xffffc90000300000-0xffffc90000701000 4198400 vgdrvLinuxProbePci+0x9c/0x210 [vboxguest] phys=f0400000 ioremap
$ sudo cat /proc/vmallocinfo | grep ioremap | awk '{print $2}' | paste -s -d '+'
16384+12288+8192+135168+4198400
$ sudo cat /proc/vmallocinfo | grep ioremap | awk '{print $2}' | paste -s -d '+' | bc
4370432
free
- /proc/meminfoの内容を元に、メモリの使用量や残量を示してくれる。なおx86(32bit)では、
lオプションはカーネルが使用するLowメモリと、プロセスが使用するHighメモリを分けて表示してくれる。なおカーネルが使用するLowメモリは、物理アドレスの1MB〜893MBまで、また各プロセスの論理アドレスの3GB〜4GBの領域を占める。x86_64(64bit)では、LowメモリやHighメモリといった区別が無いため、lオプションで表示する場合は全てLowメモリとして表示し、Highメモリは常に0として表示されるようである。
$ free -l
total used free shared buffers cached
Mem: 1017448 949096 68352 4004 88984 131476
Low: 1017448 949096 68352
High: 0 0 0
-/+ buffers/cache: 728636 288812
Swap: 839676 45872 793804
Slab
メモリの割り当てや解放を繰り返して毎回初期化するよりも、カーネルはOSにメモリを戻さずに(解放せずに)初期化した状態のまま保持し続けておき、 必要になったらそこから再利用することでパーフォーマンスが上がる。Slabはオブジェクトキャッシュとも呼ばれる。
小さい単位のメモリ割り当て・解放を、その都度メモリから自由に行うとフラグメントの問題を引き起こしやすくなるが、Slabとして保持しておいて再利用することで、少なくともスラブを利用している限りにおいてはフラグメントの問題は起こらない。
SlabのAPI
- kmem_cache_create - Slabを確保する
- kmem_cache_alloc - Slabから実際に使うオブジェクトへメモリを払い出す
- kmem_cache_free
Slabは単一のオブジェクトを連続したメモリ上に複数格納する。

- Slabがemptyになると、リープ(OSに戻す)対象となる。

- Cache Coloring - Slabのオブジェクトはページに沿って配置されているため、CPUの特定のキャシュラインに集中してしまう。別のオブジェクトがCPUの別のキャッシュラインに載るように、Slabごとに少しフラグメントを持たせてアドレスをずらす。
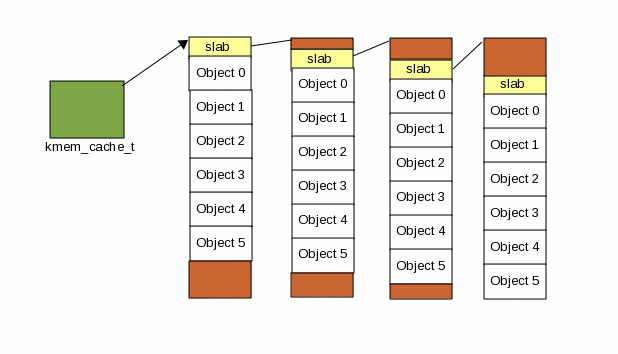
Slabが大量消費されていることでメモリを圧迫する問題(問題?)
dentryやinodeはSlabのヘビーユーザであり、それによってSlabが大量に消費されていることがある。/proc/sys/vm/drop_cachesに2 or 3を書き込むことで、Slab(SReclaimable)は解放されるが、Slabを完全に解放してしまうとLinuxとしての性能は格段に落ちる。
そもそもメモリをたくさん消費しているのはリソースを効率良く使用できている状態とも言えるので、問題なのはそれによってスワッピングが発生しているか否かであり、それは
vmstatコマンドのsi,soの項目を確認することで分かる。SlabもLRUによって管理されているはずなので、基本的にはそれにまかせるのが得策なのではないだろうか。 なお、vmstatで最初に表示される結果は起動時からの平均値であり、単位時間の結果を確認する場合には二つ目以降を確認する。
$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 1 51596 75360 71636 172804 1 10 337 19 142 462 1 2 96 1
$ man vmstat
...
Swap
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
...
- Slabのページキャッシュに対する比率を制御するには、/proc/sys/vm/vfs_cache_pressure を使う。100を基準として、Slabの比率を増やしたり減らしたりできるらしい。その他、/proc/sys/vmで管理されているパラメータについてはこちら → https://www.kernel.org/doc/Documentation/sysctl/vm.txt
Slabの肥大化で実際にスワップが発生した問題とその解決方法
- いきなり上記で書いた内容と矛盾するが、Slabの肥大化によってスワップが発生してしまった事例がある。つまり、メモリ圧迫時にはLRUに基づくSlabの解放を期待したがうまく動いてくれなかった、ということになる。その原因として考えられるのは、
dentry cacheを解放するスピードが間に合わないのか、とある。解決方法としては、tmpfsを使うことによりSlabの肥大化を回避できる、ということで、その理由としてはtmpfsがLinuxのVFSを使わないからでしょうかとのことだが、tmpfsではそもそもdentry cacheを生成しないのだろうか。この事例から「一時ファイルはtmpfsにおいて処理する」は鉄則だろう。
- negative dentry - 存在しないパスを開くと、それについてもnegativeなdentry cacheとしてキャッシュする。dentry cacheにヒットしない場合、ファイルシステムに問い合わせることでディスクI/Oが発生するが、negative entryがあればその必要が無いのでディスクI/Oを減らす効果が期待できる。negative dentryは
sar -vコマンドの結果のdentunusdが示す値に含まれているらしい。なお、negative cacheはDNSでも不要なクエリを発生させないために使われることがある。
$ sar -v | tail -n +3 | head -n4
12:10:01 AM dentunusd file-nr inode-nr pty-nr
12:20:01 AM 80492 4832 75177 1
12:30:01 AM 80506 4832 75184 1
12:40:01 AM 80495 4800 75166 1
$ man sar
...
dentunusd
Number of unused cache entries in the directory cache.
...
ページキャッシュを効率よく管理するためのアプローチ
- cachectld - posix_fadviseとPOSIX_FADV_DONTNEEDをディレクトリ単位で適用することにより、必要なページキャッシュは残しつつ、不要なページキャッシュだけをディレクトリ単位で解放する。
ページキャッシュが不要ならO_DIRECTを使うアプローチは?
openシステムコールにO_DIRECTフラグを渡すと、ファイルへの書き込みや読み込みをVFSを介さずにファイルシステムと直接行うため、メモリにページキャッシュを残すことが無い。これは、再利用することが無いと分かっている大きなファイルを開くときには、無用にメモリを使用することが無く、他のAnonymousやFile-backedなメモリに対して優しいと言える。ただし書き込みの際は、バッファへの書き込みが行われず、プロセスがディスクへの書き込み待ちで長い時間ブロックされることになるため注意が必要。
書き込みはページキャッシュとしてメモリに蓄えられた後で非同期に(flusherスレッドによってデフォルト5秒間隔で)ディスクへ書き込まれるので、通常はプロセスが書き込みでブロックされることはない。一時的にメモリを消費してしまうものの、ディスクへ書き込んだ直後に該当のページキャッシュを解放するような仕組みがあっても良さそう。
ramfs
- ramfsはtmpfsのようにメモリ上に作成されるファイルシステムだが、ramfsの方は物理ディスクがないにも関わらず、File-backedとして登録されるため、ディスクにスワップされることがない。
")
プロのための Linuxシステム構築・運用技術 (Software Design plus)
- 作者: 中井悦司
- 出版社/メーカー: 技術評論社
- 発売日: 2010/12/22
- メディア: 大型本
- 購入: 21人 クリック: 411回
- この商品を含むブログ (38件) を見る
コード最適化についての考察
文字列のリストとその出現数をカウントして多い方からN個取得する処理を考える。単純にやろうとすれば、とにかく文字列とその出現数をkey/valueとしてカウントしていき、最後にvalueでソートして多い方からN個取得すればいい。
ただし、Nが非常に小さい場合、このやり方は効率が悪い。つまり例えば、key/valueが1,000,000個あったとして、その中で多い方から5個取り出す場合、1,000,000個のリストをソートすることになり、それだけでO(nlogn)かかるが、Nが小さい場合にはこのソートは必要ない/ほとんど無駄なはずである。
以下の通り実装して、計算にかかる時間を測定した。
- take_top_n_by_sort() - 単純に全てのkey/valueをカウントして最後にvalueでソートする方法
- take_top_n_no_sort - ソートを使わず、出現数の多いN個を随時更新していく方法
- take_top_n_no_sort2 - 出現数の多いN個から最小の出現数を取得する処理をなるべく行わない方法
C++についていえば、このような用途でmapを使う必要性は無いと言える。mapはkeyがソートされたデータ構造となっているが、keyによるvalueの探索にはBinary SearchによるO(logn)が必要になる。一方、unordered_mapはハッシュを使用しており、探索はO(1)で済む。
また、Javaにはmapの実装としてTreeMapやHashMapがあるが、このような用途ではHashMapを使うべきだろう。他の言語でも、key/valueのデータ構造は必ずといって良いほど標準で実装されているが、C++のmapのようなものはあまり見ない。
ただ、これをMacとLinux(Google Compute Engine - vCPU 1)で実行してみたところ、Macの方がSortが10倍以上速いため、keyが5Mくらいでは、Sortを使った方法の方でも速くなった。Clang/LLVMではC++11におけるsort()がかなりうまく最適化されているようだ。以下記事を見ても、Clangが最も速いことが分かる。
- 実装はこちら Take TOP N list from large amount of keys in C++11 · GitHub
- パラメータは、10,000,000個の文字列、各文字列の文字数は5、リストから5個取得
#define SIZE 10000000 #define CHARS 5 #define TOPN 5
- インプットデータは以下のように正規分布に従って乱数を生成することにより出現数に偏りを持たせているため、文字列の組み合わせ総数は11881376だがそれよりかなり少なくなっている
void make_input_data(vector<string>* out){ mt19937 mt(1); normal_distribution<double> dist(13.0,6.0); for(auto i=0;i<SIZE;i++){ string s; for(auto j=0;j<CHARS;j++){ s.push_back((char)(((int)dist(mt))%26+65)); } out->push_back(s); } }
- Macでの実行結果
$ g++ --version Configured with: --prefix=/Applications/Xcode.app/Contents/Developer/usr --with-gxx-include-dir=/usr/include/c++/4.2.1 Apple LLVM version 7.0.2 (clang-700.1.81) Target: x86_64-apple-darwin14.5.0 Thread model: posix $ sysctl -a machdep.cpu machdep.cpu.max_basic: 13 machdep.cpu.max_ext: 2147483656 machdep.cpu.vendor: GenuineIntel machdep.cpu.brand_string: Intel(R) Core(TM) i5-4258U CPU @ 2.40GHz ... machdep.cpu.core_count: 2 machdep.cpu.thread_count: 4 $ g++ take_top_n.cpp -std=c++11 $ ./a.out Elapsed time for sort() with 5045629 keys : 815ms Elapsed time for take_top_n_by_sort() : 15689ms LMOOM LMKNK HLLMM MOKOO NPNKH Elapsed time for take_top_n_no_sort() : 47057ms NPNKH HLLMM LMKNK LMOOM MOKOO Elapsed time for take_top_n_no_sort_with_flag() : 15612ms NPNKH HLLMM LMKNK LMOOM MOKOO
- Linuxでの実行結果
$ g++ --version g++ (Debian 4.9.2-10) 4.9.2 Copyright (C) 2014 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. $ cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 63 model name : Intel(R) Xeon(R) CPU @ 2.30GHz stepping : 0 microcode : 0x1 cpu MHz : 2300.000 cache size : 46080 KB physical id : 0 siblings : 1 core id : 0 cpu cores : 1 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc eagerfpu pni pclmulqdq ssse3 f ma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm xsaveopt fsgsbase bmi1 a vx2 smep bmi2 erms bogomips : 4600.00 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual power management: $ ./a.out Elapsed time for sort() with 5045954 keys : 10050ms Elapsed time for take_top_n_by_sort() : 25432ms NOLPL NOKMM PJOMO LMNMO NLOOM Elapsed time for take_top_n_no_sort() : 33195ms NOKMM NLOOM LMNMO PJOMO NOLPL Elapsed time for take_top_n_no_sort_with_flag() : 16060ms NOKMM NLOOM LMNMO PJOMO NOLPL
コンパイラによる最適化
- Macのg++に
-O3をつけて実施した結果、およそ2倍くらい速くなる
$ g++ take_top_n.cpp -std=c++11 -O3 $ ./a.out Elapsed time for sort() with 4787637 keys : 331ms Elapsed time for take_top_n_by_sort() : 7743ms LMKNK LMOOM HLLMM MOKOO NPNKH Elapsed time for take_top_n_no_sort() : 19158ms NPNKH HLLMM LMKNK LMOOM MOKOO Elapsed time for take_top_n_no_sort_with_flag() : 8985ms NPNKH HLLMM LMKNK LMOOM MOKOO
ファイルシステム(ext2/ext3/ext4)の基礎まとめ
ext2

スーパーブロックには全体のi-node数など、グループデスクリプタにはそのブロックグループのi-node数など、i-nodeにはファイルのメタデータとデータブロックのアドレスなど、が記録されている
- スーパーブロックはバックアップされており、
mkfs.ext2 -nでバックアップされたブロックを確認することができ、mkfs.ext2 -bでそのブロックを指定することで復旧できる
- スーパーブロックはバックアップされており、
間接ブロック参照 - ext2のi-nodeにはデータが保存されているブロック番号を格納するサイズ15のテーブルがあり、そのうち#0〜#11は直接ブロック参照(ブロック番号を格納する)、#12は1段間接ブロック参照(ブロック番号を格納したテーブルを参照する)、#13は2段間接ブロック参照(ブロック番号を格納したテーブルを参照するテーブルを参照)、#14は3段間接ブロック参照、に使用される
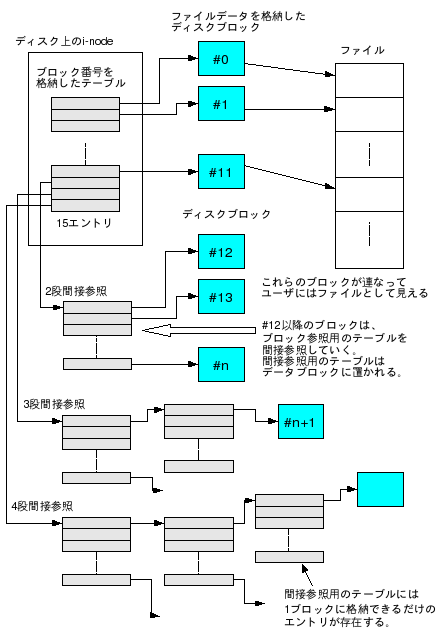
間接ブロック参照によって1ファイル4TBまでブロックを参照できるが、i-nodeのメタデータにあるブロック数が2TB(ブロックサイズが4KBの場合)までしか管理できないので、そちらが1ファイルサイズの限界を決めている
大きいサイズのファイルになると間接参照が多くなるため、書き込みや読み込みの性能が悪くなる
ext3
ジャーナリング
- データの更新処理を、不可分(アトミック)な一つのトランザクションに集約して記録することで、ファイルシステムの整合性を維持するための仕組み
- たとえファイルを削除するという単純なトランザクションの中でも、スーパーブロックやファイルのメタデータに対する様々なステップ処理が存在するため、その途中で不正なシャットダウン(アンマウント)が発生し、一部のステップ処理のみが実行される状態になるとメタデータの整合性が崩れる
- ジャーナルログがあれば、不正なアンマウントが発生してそのパーティションが
cleanな状態でなくなっても、メタデータと実データとの不整合を復旧するだけでよい - ただしext3であっても、何らかの不正な書き込みが発生してメタデータの整合性が壊れると、fsckによるステップ処理単位での復旧が必要になるし、fsckを実施していない期間がある一定期間を超えるとパーティション全体の整合性を確認することになる
O+P Insights: Improving Ext3 performance with an external journal on an SSD Disk

- 作者: 高橋浩和,小田逸郎,山幡為佐久
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2006/11/18
- メディア: 単行本
- 購入: 14人 クリック: 197回
- この商品を含むブログ (119件) を見る
fsck
- メタデータの矛盾を取り除くコマンド。壊れたデータを復旧するわけではなく、メタデータの整合性が取れるように壊れた部分を排除する。
- ファイルシステムには定期的にfsckを実行するオプションがある。ジャーナルログを採用しているファイルシステムであっても、マウントを実行した回数や前回fsck実行からの期間、によってサーバ起動時にfsckが発動してパーティション全体を走査することによる起動遅延が発生することがある。
$ sudo tune2fs -l /dev/sda1 | egrep -i "mount count|check" Mount count: 16 Maximum mount count: -1 Last checked: Sun Jun 19 00:06:19 2016 Check interval: 0 (<none>)
- fsckのチェックによってファイルシステムの整合性を保つためにディレクトリやi-nodeの内容が破棄されることで、参照不可能になったデータブロックの内容は
/lost+foundディレクトリに#とi-node番号をファイル名として退避される。
kjournald
- トランザクションを、定期的にディスク上のジャーナルログ領域に書き込む(コミットする)デーモン
- kjournaldの書き込み間隔はデフォルトで5秒で、この間隔は信頼性と性能(データの永続化とDisk I/Oの回避)のトレードオフとなる
ジャーナルモード
- ジャーナルモードはマウントオプションとして
data=journalなどとして指定する
journal
- メタデータと実データのトランザクションをコミットしたのち、メタデータと実データをディスク上のデータ領域に書き込む
- 完全にデータを冗長化することができるが、書き込み性能は悪い
- ジャーナルログとデータ領域に不整合が発生することがない
ordered
- 実データが書き込まれたのち、メタデータのトランザクションをコミットする
- つまり、実データの書き込み順序と、トランザクションへのコミット順序が、常に一貫性を保つ(シーケンシャルに実行される)ことを保証する
- 実データがディスク上のデータ領域に書き込まれる前に不正なアンマウントが発生すると...
- ジャーナルログから、ディスク上のデータ領域のメタデータを復旧する
- 新しい実データが(バッファには書き込まれているものの)ディスク上のデータ領域に書き込まれていない場合は、実データは復旧できない
- 新しい実データの復旧はできないが、ジャーナルログによるメタデータの復旧は可能になる
writeback
- 実データの書き込み順序と、トランザクションへのコミット順序が、一貫性を保てない
- 実データがデータ領域に書き込まれる前に不正なアンマウントが発生すると...
- ジャーナルログはシーケンシャルに書き込まれたものであることが保証されていないため、メタデータの復旧が正しく行われないことがある
- 書き込み性能は最も良いが、メタデータの復旧がうまくいかない場合があることを許容する動作になる
MySQL(InnoDB)との関連について一言
WAL / Double Write
- WAL (Write Ahead Log) は、トランザクションがコミットされたときに、トランザクションの内容をディスク上のログ領域に書き込む(更新データはバッファ上に残っている)
- Double Writeは、バッファからディスクへフラッシュされたときに、ディスク上のデータ領域に書き込む前に、ダブルライトバッファ領域に書き込む(更新データのコピーを保持することができる)
- これらの領域はシーケンシャルに書き込まれていくので、ディスク上のシーク時間が短く、I/Oに必要な時間が短い(Double Writeといっても書き込み時間が二倍になるわけではない)
ext4
遅延確保 - ext3まではバッファ書き込み時にディスク上のブロック割り当てを行うが、これをバッファ書き込み時からディスク書き込み時にまで遅延することで、複数の書き込みをまとめてブロック割り当てを行うことができるため、連続したブロックを割り当てやすくなりフラグメンテーションを起こりにくくする
エクステントの導入 - 大きなファイルに対して、複数のブロックの格納場所を全て保持する(かつ、多段参照のオーバーヘッドがある)と非効率なため、隣接するブロックに対してその格納場所を配列として保持することにより効率化する(先頭ブロックの格納場所と連続ブロック数(オフセット)、を組み合わせて複数保持する)
- 一つのi-nodeに格納できるエクステントは限りがあるので、Extent-IndexをB-treeとして保持することで検索効率を上げる
https://www.usenix.org/legacy/event/lsf07/tech/cao_m.pdf
- ナノ秒単位のタイムスタンプ
# ext4 $ mount | grep " / " /dev/mapper/fedora-root on / type ext4 (rw,relatime,seclabel,data=ordered) $ stat /etc/fstab File: ‘/etc/fstab’ Size: 465 Blocks: 8 IO Block: 4096 regular file Device: fd01h/64769d Inode: 130747 Links: 1 Access: (0664/-rw-rw-r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: system_u:object_r:etc_t:s0 Access: 2017-02-14 09:24:21.453460379 +0900 Modify: 2014-03-01 18:43:24.267325166 +0900 Change: 2014-03-01 18:43:24.267325166 +0900 Birth: -
# ext3
$ dd if=/dev/zero of=ext3img bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 0.386865 s, 271 MB/s
$ mkfs.ext3 -F ext3img
mke2fs 1.42.12 (29-Aug-2014)
Discarding device blocks: done
Creating filesystem with 102400 1k blocks and 25688 inodes
Filesystem UUID: 235bf453-34b4-430e-b508-4279dbc61c6c
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Allocating group tables: done
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
$ sudo mkdir /mount
$ sudo mount -t ext3 -o loop ext3img /mount/
$ mount | grep ext3
/home/nishidy/ext3img on /mount type ext3 (rw,relatime,seclabel,data=ordered)
$ sudo touch /mount/file
$ sudo vim /mount/file
$ stat /mount/file
File: ‘/mount/file’
Size: 12 Blocks: 4 IO Block: 1024 regular file
Device: 700h/1792d Inode: 14 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Context: unconfined_u:object_r:file_t:s0
Access: 2017-02-14 09:31:39.000000000 +0900
Modify: 2017-02-14 09:31:25.000000000 +0900
Change: 2017-02-14 09:31:25.000000000 +0900
Birth: -
チェックサムの導入 - ジャーナルログにチェックサムが追加されて、ジャーナルログに対するチェックサムチェックが可能になり、信頼性が向上する
H-Tree - ext2/ext3ではディレクリ構造が連結リストにより管理されていたが、連結リストでは探索にO(n)の時間がかかるため、B-Treeの改良版であるH-Treeが採用されており、これにより探索時間が短縮される*1
- 動的なi-node確保 - ...
B-Tree

- Balanced Tree(平衡木の一つ)
- 検索における計算量
- 木に含まれる全てのキーの数をn、ノードが持つ子の最大数をm(ノードが持つキーの最大数をm-1)とする
- ノードが持つ子の平均数は m/2 になり、よって木の深さは
となる
- ノードのキー探索回数は、mが大きいときにはBinary Searchによってlog mとなる(キーはソート済み)
- よって計算時間は log m *
e.g.
30 50 70 | 10 20 | 40 | 60 | 80 90 |
B+-Tree
e.g.
30 50 70 | 10 20 | 30 40 | 50 60 | 70 80 90 |
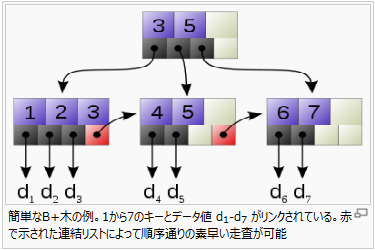
Oracle の B*Tree インデックスの内部構造についてお勉強中(その1) - drk7jp
B*-Tree
- B+-Treeを拡張して、ノードの持つキー数をなるべく多く保つ(as dense as possible)ことで、メモリ利用効率や検索速度が向上
- 最大数のキーを保持しているノードに挿入する場合、(B+-Treeのように)即座にノードを分割するのではなく、隣のノードに空きがある場合は、親ノードを介した回転を伴って、隣のノードにキーを移動させる
- 隣のノードも最大数のキーを保持している場合、二つのノードを三つのノードに分割する
")
- 作者: ドナルド・E.クヌース,Donald E. Knuth,有澤誠,和田英一
- 出版社/メーカー: アスキー
- 発売日: 2006/04/01
- メディア: 単行本
- 購入: 2人 クリック: 74回
- この商品を含むブログ (22件) を見る
XFS
- アロケーショングループ
Btrfs
- コピーオンライト(CoW)
- データ更新時にスナップショットを作成することで、障害時の実データのロールバックが可能に
- データコピー時には実体への参照のみを作成することで、高速な処理が可能に(データ更新時に実体を作成)
- 透過圧縮
- ディスクに書き込む・読み込む際にファイルシステムのサポートによってデータを圧縮・解凍する(LZO、ZLIB)
- 圧縮・解凍のためにCPU使用率が上がるが、書き込む量を減らすことで、ディスクスペースの利用効率だけでなく、ディスクI/Oの効率を上げる効果がある
- LVMのようなボリューム管理機能
...
www.slideshare.net
ハードリンクとシンボリックリンクの違い
- ハードリンクは、オリジナルファイルと同じi-node番号を持つファイル。i-node番号が同じファイルのため、オリジナルファイルをどのパスに移動しても、ハードリンクはパスに関係無くオリジナルファイルへ追従することができる。ただし、ハードリンクはオリジナルファイルと別のファイルシステム上には作成できない。i-node番号体系が異なるためである。
- i-nodeには参照カウントがあり、ハードリンクが作成されるとオリジナルファイルの参照カウントがインクリメントされる。ハードリンクが削除されると参照カウントはデクリメントされる。参照カウントが0になった時点で実体のブロックは解放可能となる。
シンボリックリンクの実体はオリジナルファイルへのパスである。従って、シンボリックリンクはハードリンクと別のファイルシステム上にも作成できる。ただし、オリジナルファイルを移動したり削除したことに気が付かない。
ディレクトリエントリは、ファイル名とi-node番号を対としたリストを持つ。従って、i-nodeにファイル名の情報は無い。"."は自分自身のディレクトリのi-node番号を指すため、ディレクトリ作成時にそのディレクトリの参照カウントは2となる。".."は親ディレクトリへのi-node番号を指すため階層構造をルート方向へ追跡することができる。
chroot配下でchroot外へディレクトリへリンクする場合
FeliCa/Suicaについて調べた
Suica(FeliCa)がiPhone7とApple Watch series 2に搭載されることになったので、この機会にいろいろ調べてみた。まだ、憶測の域をこえないところはある。
Sony Japan | FeliCa | FeliCaとは | FeliCaって何?
- SuicaはFelicaに対応した一つのアプリケーション
FelicaはNFCフォーラムで規定されているNFC国際規格のType-Fである
- その他に市場投入されているTypeとしてType-A(タスポ etc.)/Type-B(運転免許証 etc.)がある
国際規格については複雑な事情がある 近距離無線通信 - Wikipedia
2010年のFeliCaチップの出荷台数(最近の情報ではないがアジアのみに集中していたことが分かる)
→ 現時点で国際的にNFCでどのくらいType-Fが占めているのか知りたい(おそらく非常に少ない)
電源を持つリーダ/ライタ端末から電磁波を発生させて電磁誘導を起こし、カード側ではその反射波を変化させることで振幅を制御してデータを載せる(Type-Fの変調方式はASK=振幅偏移変調)
- 今回のiPhone/Apple Watchの対応は、カード(FeliCa IC)とリーダ/ライタ機能、の両方を搭載するはず
- ただし、iPhone/Apple Watch内部で電波を使う必要は無さそう (FeliCa ICとリーダ/ライダ機能が物理的に分かれている必要すらない) → FeliCa対応のiPhone 7に「総務省指定」刻印があるのに、同じくFeliCa対... - Yahoo!知恵袋
- でも、NFCは電力は相当小さいはずだけど無線の認可は本当に必要なんだろうか NFCについてのまとめ | インバウンドマーケティング/Facebookアプリ/Web制作 Hivelocity ハイベロシティ
- "2.設置許可不要設備 無線通信等への影響が少ないと判断される設備については、 個別の許可を不要としており、次のような設備があります。" 認可は不要だけど"MIC/KS"の表示は必要とのこと(もしかすると、送信電力が弱い、のではなく受信のみ、なのかも) 総務省 電波利用ホームページ | 高周波利用設備の概要
- 海外版のiPhoneでも搭載されているNFCチップの型番は同じなので、ハード的にはFliCaに対応しているらしい 海外版のiPhone 7にもFeliCaは内臓していた。ただし・・・。
- Type-F(Felica)は対称通信、つまりリーダ/ライタ側からカードへの通信とその逆の通信において、13.56MHzを使う
Type-A/Type-Bは非対称通信、つまりリーダ/ライタ側からカードへの通信において13.56MHzを使い、その逆の通信においては13.56/16=848KHzを使う
非対称通信の方は、周波数帯が違うので全二重通信が可能になるが、FeliCaが半二重通信となる対称通信を採用した背景として、上位層=アプリケーションのスループットを考えると対称通信の方が良くなるから 非接触ICに最適化された「FeliCa」の正体 − @IT
Apple Watchは電源が心配(通常使用で18時間)だが、電源が切れてもFelicaが使えなくなることはなさそう
- "アプリケーションを開く必要はなく、デバイスをスリープ状態から復帰させる必要さえありません。" Apple Pay - 始め方 - Apple(日本)
- 電源が切れた場合には、Apple Watchのリーダ/ライタ機能を起動できずにFeliCa ICチップにはアクセスできなくなるので、Apple Payでのチャージ等はできなくなるだろう
SuicaのカードをiPhone7/Apple Watch Series 2にかざして取り入れた場合、そのSuicaのカードは二度と使用できなくなるらしい Rebuild: Aftershow 157: Gigaflops Per Yen (hak)
How to protect from fraud?
- 中央サーバでトランザクションを一元管理するしかないが、Suicaのような高速な応答性を求められるアプリケーションで、それをどのように実現するか?
- 改札機器端末 → 駅 → 中央サーバ の階層型分散システム
- 各階層でトランザクションのキャッシュを持つことで、中央サーバが応答不能になっても即座にサービス停止とはならない
→ 改札機器端末は各アカウントの3日分のトランザクションを蓄えられる容量があるらしい - 上階層へのトランザクションの更新処理は、キューに溜める非同期型になっているため、入場時の改札機器端末の応答速度は、カードと改札機器端末の間の処理にかかる時間に縮められる
- 改札端末には各駅までの運賃がキャッシュされており、運賃計算時に即座に反応できるようになっている
- 出場時の改札機器端末の応答速度を速めるため、入場時にある程度前もって計算してカードに保存しておく(e.g. 入場駅から定期区間の始めまでの運賃)
- 各階層でトランザクションのキャッシュを持つことで、中央サーバが応答不能になっても即座にサービス停止とはならない
How to avoid data break?
Linuxのブートシーケンスの基礎まとめ
ファームウェア(BIOS or UEFI*1)が
- マザーボードのROMからメモリにロードされて実行開始し、ハードウェアをスキャン(POST - Power-On Self Test というハードウェアの自己診断を)する
- [BIOSの場合] プライマリHDDのMBR(先頭のセクタ(512バイト))を見る
- [UEFIの場合] プライマリHDDのGPTヘッダ(LBA1 or 最終セクタ)を見る

GPTとMBRはどのように違うのか? - かーねる・う゛いえむにっき
BIOS/UEFI/MBR/GPT
- MBRでは232≒2.2TBまでのディスクしか扱えない
GPTでは264≒8.5ZBまでのディスクを扱うことができる
BIOSはIntel CPUのリアルモード(16bitモード)でないと起動できないため、1MBまでのメモリしか利用できない
- UEFIはプロセッサ非依存のため、32bitプロセッサなら32bit命令が、64bitプロセッサなら64bit命令が使えるため、潤沢なメモリを利用できる
MBRのパーティションテーブルには四つのパーティション構成情報が書き込める (四つ以上は、四つ目を拡張パーティションテーブルとして対応)
- MBRの最後の2バイトは
0xaa55というMBR signatureが書き込まれている
$ sudo hexdump -s 500 -n 12 /dev/sda 00001f4 0000 0000 0000 0000 0000 aa55 0000200
一方、GPTは128までパーティションが管理でき、物理や論理といった煩雑な管理は必要ない
末尾にもGPTヘッダがあり冗長構成となっている
2TB以上のディスクは
- MBRでは扱うことができない and
fdiskコマンドでは扱うことができない GPTを使う必要がある and (
partedorgdiskコマンドを使う必要がある )追加した2TB以上のディスクにパーティションラベルを付ける
# parted /dev/sdd (parted) mklabel gpt
ブートローダ(GRUB or LILO)が
GRUB2
- MBRに含まれるGRUB Stage 1をロードする
- GRUB Stage 1が、MBRと最初のパーティションの間に置かれているGRUB Stage 1.5をロードする
- Stage 1.5が、bootパーティションのファイルシステムをマウントするためのドライバを持っており、/boot/grub/からStage 2をロードする
- Stage 2が、カーネル選択メニューを表示する
initrd/initramfs
- initrdはブロックデバイスをgzip圧縮したもの
- initramfsはファイルシステムをcpioでアーカイブしたものをgzip圧縮したもの
- initrdにカーネルモジュールを追加しようとするとマウントが必要(etc.)
→ 扱いにくいのでObsolete
→ 現在では一般的にinitramfsを使う - initrdに含まれるファイルにアクセスするためにループバックマウントされる
initrd/initramfsの必要性
- カーネル本体に(ドライバ等の)モジュールを直接組み込んでおくよりも、カーネル外部に(ファイルとして)存在するカーネルモジュールを必要なときに必要なだけ組み込む方が、カーネル本体を軽量にかつ汎用的に扱うことができる
- ルートファイルシステムをマウントするために必要なファイルシステムのドライバを、別のルートファイルシステムにモジュールとして保存しておいて、マウントする前にカーネルにロードする
- この「別のルートファイルシステム」を担うのがinitrd/initramfsであり、これは「初期ルートファイルシステム」、あるいは、ramfsとしてメモリ(RAM)上にマウントされるため「初期RAMディスク」、と呼ばれる
vmlinuz/vmlinux/bzImage/zImage
- bootパーティションには、vmlinuzと呼ばれる、カーネルイメージを含むファイルが置かれている
- vmlinuzは、カーネルイメージ(vmlinux)をgzip圧縮したものと、圧縮されたカーネルイメージを伸張し展開するコードをそれ自身に伴った形式ものである
- このファイル形式をbzImageという
- なお、zImageでは512KB以下のイメージしか扱えない
uImage
- U-Boot用のカーネルイメージのファイル形式
- U-Bootは、主に組み込み用途で使われるブートローダで、ネットワークブート(PXEクライアント)の機能を持つなど、高機能版のブートローダ(GRUBでネットワークブートをする場合は、おそらくNIC側のPXEクライアント機能を使う必要がある)
System.map
- System.mapは、vmlinuxに対するnmコマンドの実行結果であり、カーネルに関するメモリアドレスと型、シンボルの対応テーブルを表す
- nmは、実行形式のファイルやライブラリなどからシンボルテーブルを取得するためのコマンド
- ブートに必要なデータではなく、Kernel PanicやOopsが発生した際のデバッグに使われる(実行時のメモリアドレスからシンボルを特定する)
kexec
カーネルが
- ハードウェアリソースに対応する初期設定やデバイスドライバの初期設定を行う
- idleプロセス(PID=0)を起動する
- initrd/initramfsを展開して、初期ルートファイルシステムをramfsとしてマウントする
- [initrdの場合] /linuxrcを、一時的なinitプロセス(PID=1)として起動する
- [initramfsの場合] /initを、一時的なinitプロセス(PID=1)として起動する
- 初期ルートファイルシステムに置かれているカーネルモジュールをロードして、様々なファイルシステムでフォーマットされているパーティションを認識する
- 初期ルートファイルシステムから、読み込み専用でマウントしたルートファイルシステムへマウントポイントを移す
- [initrdの場合] 一時的なinitプロセスの終了後に、/sbin/initを実行して、initプロセス(PID=0)を起動する
- [initramfsの場合] /initが、exec /sbin/initを実行して、initプロセス(PID=0)を起動する(execは現在のプロセスを別のプロセスで置き換える)
Systemd
- /sbin/initは、現在systemdに置き換えが進んでおり、単に/sbin/initがsystemdへのシンボリックリンクになっているLinuxディストリビューションも存在する
- systemdは、サービスの起動を並列に実行することによる起動処理の高速化、cronやxinetd(リソース効率化のため通信を検出した際にそのポートに対応するプロセスを起動するスーパーデーモン)に対応する機能の集約、cgroupによるリソース制御を用いたプロセスの優先度管理、などを行う
initプロセスが
- /etc/inittabに書かれている通りrunlevelを設定し、該当する/etc/rc.d/rcXを実行する
- スクリプトを実行する際は、forkによってinitプロセスがそのスクリプトを実行するプロセスの親プロセスとなる
- 読み込み専用でマウントされたルートファイルシステムに対して
fsckを実行*2し、実行後に読み書き可能で再マウントする - initプロセスが、/etc/fstabに書かれている通り各パーティションをマウントする
runlevel
- runlevelの定義はOSに依存するが、0:停止、1:シングルユーザ、2:マルチユーザ(ネットワーク無、Xディスプレイ無)、3:マルチユーザ(ネットワーク有、Xディスプレイ無)、5:マルチユーザ(ネットワーク有、Xディスプレイ有)、6:リブート、のパターンが多い
- Sで始まるファイルは起動用スクリプト(S=Start)であり、Kで始まるファイルは停止用スクリプト(K=Kill)になる
…
AVL木の更新状況が見たい
AVL木は平衡二分木の一つで、ノードの追加・削除のたびに木の再構成を行い、検索時の計算時間を最小に抑えるようなデータ構造を維持する。木の再構成を行わない場合、最悪の場合には木の片側のみを使ってしまい検索時にO(n)の時間がかかってしまうが、再構成を行うことにより木を厳密に平衡に保つためO(logn)の時間で検索できる。更新・削除にも時間がかかるが、その分検索の時間を速くすることを目的としている。
実装を進めるにあたって、更新時の回転操作を正しく理解するためにも、木構造そのものを見ることが出来る方が分かり易いだろう、ということで、まず木構造をデバッグできるよう実装した。
ノードは双方向の連結リストになっているが、可視化する場合には幅優先探索によって同じ階層のノードを取得し、それをヒープ構造に入れることにした。ある階層の全てのノードがNULLになるまで、あるノードがNULLであっても子ノードの取得を続けるようにしているため、こうしておくと、あるノードの親がNULLかどうかも確認しやすい。見やすさのため、親がNULLの場合は何も出力が行わないようにする。NULLノードは[]で示している。
数字の隣はラベルで、AVL木において重要な役割を持つ。LEFT、EQUAL、RIGHT、はそれぞれ左部分木が深いか、平衡か、右部分木が深いか、が分かるようになっている。
Thanks to :
$ java AVLTree
Please input the value for root node. : 8
('q' for quit, 'p' for print, 's' for search.)
Please input. : p
8E---|
[] []
Please input. : 3
Please input. : 14
Please input. : p
8E-------|
3E---| 14E---|
[] [] [] []
Please input. : 2
Please input. : 6
Please input. : p
8L---------------|
3E-------| 14E-------|
2E---| 6E---| [] []
[] [] [] []
Please input. : 12
Please input. : 15
Please input. : p
8E---------------|
3E-------| 14E-------|
2E---| 6E---| 12E---| 15E---|
[] [] [] [] [] [] [] []
Please input. : 1
Please input. : 4
Please input. : p
8L-------------------------------|
3E---------------| 14E---------------|
2L-------| 6L-------| 12E-------| 15E-------|
1E---| [] 4E---| [] [] [] [] []
[] [] [] []
Please input. : 5
Rotate left at 6!
Please input. : p
8L-------------------------------|
3E---------------| 14E---------------|
2L-------| 5E-------| 12E-------| 15E-------|
1E---| [] 4E---| 6E---| [] [] [] []
[] [] [] [] [] []
Please input. : 7
Rotate left at 8!
Please input. : p
5E-------------------------------|
3L---------------| 8E---------------|
2L-------| 4E-------| 6R-------| 14E-------|
1E---| [] [] [] [] 7E---| 12E---| 15E---|
[] [] [] [] [] [] [] []
Please input. : 0
Rotate left at 2!
Please input. : p
5E-------------------------------|
3L---------------| 8E---------------|
1E-------| 4E-------| 6R-------| 14E-------|
0E---| 2E---| [] [] [] 7E---| 12E---| 15E---|
[] [] [] [] [] [] [] [] [] []
Please input. : 20
Please input. : p
5R---------------------------------------------------------------|
3L-------------------------------| 8R-------------------------------|
1E---------------| 4E---------------| 6R---------------| 14R---------------|
0E-------| 2E-------| [] [] [] 7E-------| 12E-------| 15R-------|
[] [] [] [] [] [] [] [] [] 20E---|
[] []
Please input. : 22
Rotate right at 15!
Please input. : p
5R---------------------------------------------------------------|
3L-------------------------------| 8R-------------------------------|
1E---------------| 4E---------------| 6R---------------| 14R---------------|
0E-------| 2E-------| [] [] [] 7E-------| 12E-------| 20E-------|
[] [] [] [] [] [] [] [] 15E---| 22E---|
[] [] [] []
Please input. : q
$
- のべ16ノードを挿入した木を100回作成(検索の確認は無し(0回))

- のべ10,000,000ノードを挿入した木を作成し、10回検索を実施して各時間を測定
- 計算時間はO(logn)、つまり対数をeとするとlog(10,000,000)=16.118で、これはO(n)と比べると、60万倍以上早い(つまり、数十〜数百msかかる可能性がある)
$ java AVLTree 10000000 10 Found node 7443458 in 11830 ns. Found node 1542990 in 7199 ns. Found node 9059491 in 5348 ns. Found node 2189518 in 5501 ns. Found node 5773482 in 3459 ns. Found node 7512803 in 4832 ns. Found node 7103487 in 6813 ns. Found node 5575799 in 5398 ns. Found node 5292306 in 84161 ns. Found node 8909173 in 20869 ns. $
実装はこちら。削除は複雑なため未実装です。
Sortアルゴリズムの消費メモリについて(続)
ソートにおいて、ソート対象の配列に対するポインタを操作すれば、各関数の中でソート対象の配列が持つ要素に対するメモリを確保する必要が無くなる。もし、ソート対象の配列の要素の型がポインタよりも小さいサイズであれば、その要素に対するメモリを確保した方が良いが、例えばソート対象の配列の要素が構造体である場合は、その要素に対するメモリ量が大きいので、ダブルポインタでポインタをソート対象として扱うべきである。ポインタのサイズはプラットフォームに依存するので、sizeof()で確認する。
ダブルポインタを用いてポインタに対してメモリを確保するソート(sort())と、データの型に対してメモリを確保するソート(_sort())、それからライブラリのソート(qsort())、を比較してみた。ソート処理全体で確保した総メモリ量と、mallocを呼んだ回数をカウントしている。なお、構造体のソート対象のキー(age)以外は、参照もしないので、初期化すらしていない。ダブルポインタを用いる方がメモリ量が小さいし速い。ただ、やはりライブラリのソートの方がかなり速い。
なお、前回のプログラムでQuick sortのmalloc回数が多かったのは、ソート対象の配列数が1になった場合にreturnしていないため。
$ ./structsort 5000000 Size of Data struct : 68 Size of a pointer : 8 (Size of short: 2) (Size of int: 4) (Size of long: 8) Quick sort (double pointer): 5.22 sec. 1045MB,3385634 Good. Sorted. Quick sort : 6.48 sec. 8887MB,3385634 Good. Sorted. Quick sort (library function) : 3.20 sec. Good. Sorted.