仮想マシンのスタックとネットワークI/Oについて
仮想化コンセプト
- 仮想マシンモニタ=VMM(Virtual Machine Monitor)は、自身の子プロセスとして仮想マシンを実行し、ユーザモードでは実行できない命令を仮想マシンが発行したときは、CPUで例外が発生するため、それをVMMが補足(trap)*1して、仮想マシンが実行すべき命令をVMMが実行すれば良い(trap-and-emulate)。
- そのためには、VMMは特権モードで実行し、仮想マシンを特権モードより低いモード(かつ、ユーザモードより高いモード)で実行すれば良い。
x86における仮想化
- リングのコンセプトには0〜3の4段階があり、リング0はハードウェアにアクセスする特権命令を実行する。つまり、カーネルモードはリング0で実行し、ユーザモードはリング3で実行する。なお、1,2は使用しない。
- x86では、「非特権命令であるためリング0以外で実行してもトラップは発生しないが、リングの状態やハードウェアリソースの状態に依存する命令」=センシティブ命令、が存在するため、仮想化コンセプト通りにVMMを実装してもうまくいかない。

- そこで、バイナリトランスレーションという技術により、VMMが仮想マシンの実行するプログラムを解析して、センシティブ命令を別の命令に置き換えるという手法が確立されたが、実装の難易度が高く、VMMの選択肢が限られていた。
Intel VT-x/AMD-Vの登場
Intel VT-xはハードウェア(CPU)による仮想化の実現支援機構で、全ての特権命令やセンシティブ命令をトラップできるようになった
リング0の状態にVM root modeとVM non-root modeの区別を提供したことで、ゲストOSをリング0(non-root mode)で動かしてもVMMがそれより上位(root mode)から制御できる
ゲストOSが特権命令を発行するとnon-root modeからroot modeへの移行(VMExit)により、制御がVMMに移されハードウェアへのアクセスなどが実行される
Intel VT-x

- AMD-V
- 性能については、バイナリトランスレーションを採用しているVMwareの方が、CPUの仮想化支援機構を利用したKVMよりも、当初は速かった。VMEntryやVMExitによるモードの移行処理のオーバーヘッドが大きかったためである。CPUの技術向上によりこれらの処理に必要なクロック数が下がり、この差は解消されていった。
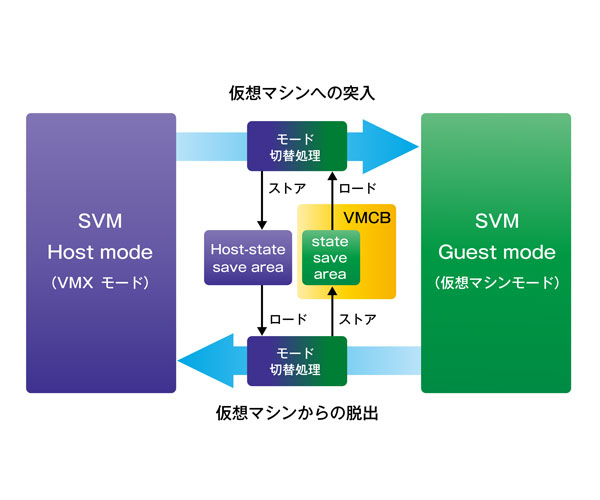
VMCS(Intel)/VMCB(AMD)
- 仮想マシンが扱う各種レジスタなどの情報を保存しておくための物理メモリ上の領域。CPUによって、VMEntryの際にはVMCSから情報を復帰し、VMExitの際にはVMCSへ情報を退避する。VMCSに保存されない情報については、VMMによって復帰・退避が行われる。
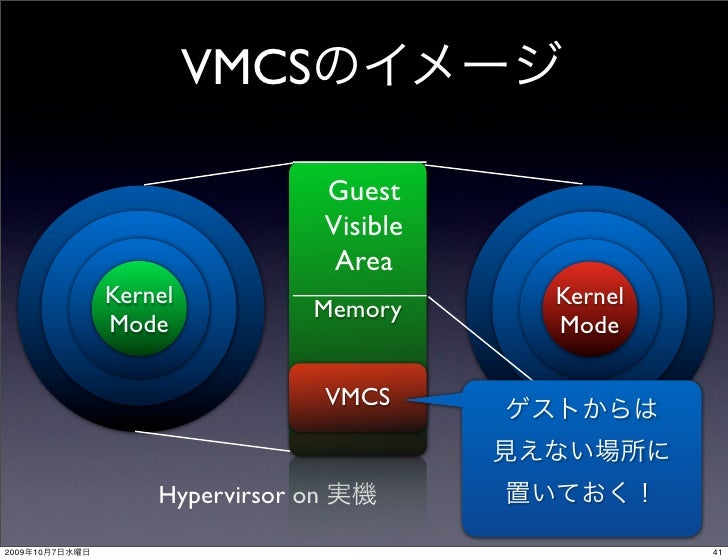
EPT (Extended Page Table)
- ゲストOSは各プロセス毎にページテーブルを持ち、仮想アドレスからゲスト物理アドレスに変換しようとするが、さらにVMMによりゲスト物理アドレスからホスト物理アドレス(実際のメモリ上のアドレス)に変換する必要がある。ソフトウェア的にTLBへの書き込みが行われる場合には、ゲスト物理アドレスからホスト物理アドレスへの変換が行われたうえで、TLBに書き込まれる。
- x86のようにハードウェア的にTLBへの書き込みが行われるアーキテクチャでは前記の方法は採用できない。よって、VMMはゲストの仮想アドレスからホスト物理アドレスへの変換表をSPT (Shadow Page Table)としてメモリ上に保持しつつ、その遷移に追従しながら管理しなければいけない。
- VMMによるSPTの管理のオーバーヘッドをなくすために、仮想マシンごとのゲスト物理アドレスからホスト物理アドレスへの変換の部分を透過的にハードウェアで実行するのがEPT。ゲストの仮想アドレスからゲスト物理アドレスへのページテーブルと、ゲスト物理アドレスからホスト物理アドレスへの拡張ページテーブル(EPT)を、両方ともTLBで処理する。ゲストOSのページテーブル変更=SPTの更新時のVMExit/VMEntryのオーバーヘッド、をなくすことができる。
VPID (Virtual Processor Identifier)
- TLB(Translation Lookahead Buffer)は、直前に利用したプロセスのページテーブルをCPUキャッシュに載せて再利用することで、メモリアクセスを減らして高速化する。
- 仮想マシンのTLBと、VMMのTLBは異なるため、VMEntry-VMExitの際に(つまり仮想マシンのプロセスがシステムコールを呼んで特権命令を実行する度に)、TLBがフラッシュされてしまい、TLBの本来の意義が果たせなくなってしまう。
- そこで、TLBをそれぞれの仮想マシンとVMMで使い分けてCPUキャッシュに保持するために、VPIDを導入しそれぞれのTLBを識別して管理できるようにした。
完全仮想化
- ゲストOSを変更しない完全仮想化であらゆるOSをゲストとして実現する。KVMではQemuによるエミュレーションを利用するが、CPUのエミュレーションは非常に遅いので、Intel-VT/AMD-Vの仮想化支援機構が無いと実用性が無い。
- KVMではHypervisorはLinuxホスト上でqemu-kvmと呼ばれる一つのプロセスとして動作し、kvm.koというカーネルモジュールを介して特権命令を実行する。
準仮想化
- ゲストOSを一部変更することによって、仮想化を実現する。仮想マシンをリング1で実行することで、CPUの仮想化支援機構を必要としない方式。
- Xen/VMware ESXではHypervisorは物理ハードウェア上で直接動作する。
Nested VMM
- CPUの仮想化支援機構を、ゲスト上のVMMにも提供する機能。KVM on KVM などが可能になる。仮想マシンで
/proc/cpuinfoにvmxやsmxといった単語が見える場合は、Nested VMMが有効。
I/Oの仮想化
Intel VT-d
- チップセットが提供する機能で、仮想マシンのデバイスI/Oをより高速にする。
- 特にPCI機器を用いてIOMMUを行う場合、PCI PassThroughと呼ばれる。これは、排他的にデバイスを割り当てるため、ホストや他の仮想マシンからは該当のデバイスは見えなくなる。
SR-IOV
- PCI Expressデバイスが排他的な仮想デバイスの機能(VF)を提供することで、IOMMUを有効にしながらも複数の仮想マシンで物理デバイスの共有が可能になった。
- NICデバイスの場合、仮想スイッチによるCPUを用いたホスト-ゲスト間のトラヒック転送を担う必要がなくなり、単一の物理デバイスを共有しながらも物理NICのネイティブな処理能力を発揮することができる。
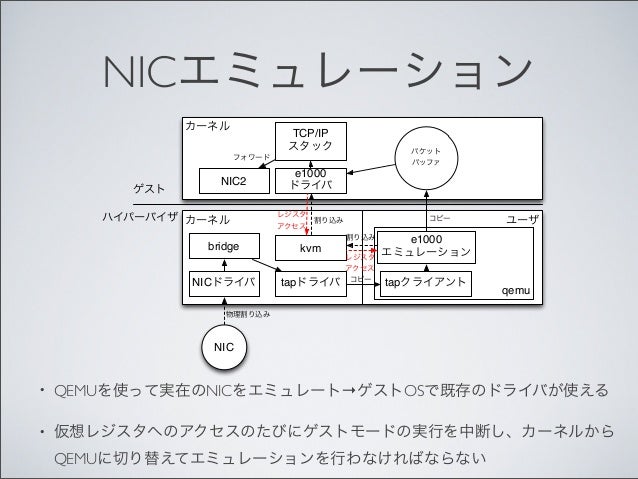
仮想デバイスによるNICエミュレーション
VMMが、エミュレートした仮想デバイスを仮想マシンに対して提供し、仮想マシンにはその仮想デバイスに対するデバイスドライバがインストールされる。それぞれ、バックエンド、フロントエンド、と呼ばれる。
- e1000
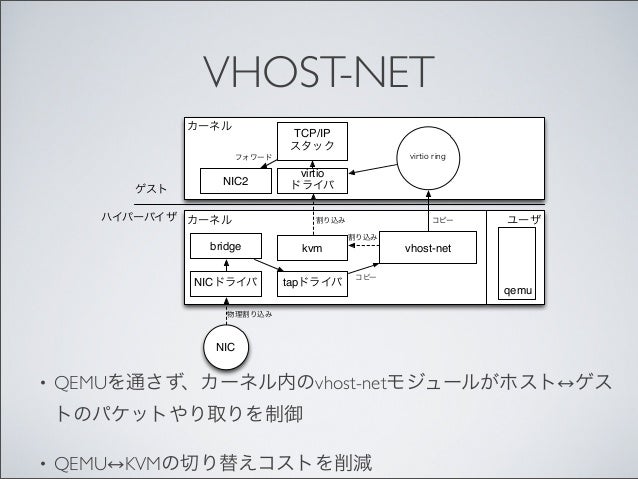
- virtio

- vhost-net
Thanks to
www.slideshare.net
ネットワークI/O
- パケット受信処理

- NAPI - ハードウェア割り込みが多くて性能が上がらない状況を改善するため、ハードウェア割り込みが発生した際にいったん割り込みを禁止して、カーネルが物理デバイスのメモリをポーリングする、という仕組みを提供するLinux Kernel API。ポーリングはプロセススケジューリングによって実行されるため、割り込み禁止からポーリングの間にNICに到着したパケットをまとめてソフトウェア処理できるため効率が良い。

受信パケットを別のCPUで処理すると、プロセススケジューリングに依存してパケット処理の順序が変わってしまうことでreorderingが発生する頻度が多くなることを避けるため、受信パケットのソフトウェア上の処理は特定のCPUに集中してしまう。
RSS (Receive Side Scaling) - NICに複数の受信パケットキューを持たせ、パケットの5 tuplesをハッシュとしてキューに振り分け、それぞれのキューを別のCPUに割り当てて処理する制御を実現したもの。5 tuplesで一意にCPUを振り分けることで、上記のようなreorderingの頻発が起こるのを防ぐ。
RFS (Receive Flow Steering) - RSSの仕組みをソフトウェアとして実現し、さらにアプリケーションプロセスがユーザ空間で最後に処理したCPUを記憶して、動的にそのCPUをキューに割り当てる。それによってCPUのキャッシュヒットを高める。NICからのDMAでパケット(フレーム)をリングバッファに取り込んだ後にプロトコルスタックの処理をCPUで行う際のキャッシュを活用することによる性能向上が見込める。
netmap
www.slideshare.net
http://www.coderplay.org/networkingdev/Linux-Kernel-Networking-Packet-Receiving.htmlwww.coderplay.org

- 作者:Jonathan Corbet,Alessandro Rubini,Greg Kroah-Hartman
- 出版社/メーカー: オライリージャパン
- 発売日: 2005/10/22
- メディア: 単行本
Intel DPDK
- パケット処理におけるLinuxカーネルの処理がオーバーヘッドとなりつつあり、さらにSR-IOVなどNICと(ユーザスペースで動作する)仮想マシンを直接繋げる技術も登場している。
- Intel DPDKは、Linuxカーネルをバイパスし、ユーザスペースでデバイスドライバを動かして、直接パケットをアプリケーションに届けるようなプログラムを実装するためのSDKを提供する。
- PMD(Poll Mode Driver)と呼ばれる特別なデバイスドライバを特定のCPUで動かしてNICを監視し、パケットをユーザスペースのアプリケーションに届ける。また、UIO/VFIOといったユーザスペースでデバイスドライバを動かすためのカーネルモジュールを使用する。
- Hugepageによって1ページあたりのサイズを大きくすることで1ページにバッファを収めることができるため、仮想メモリ空間で連続的なメモリを実現する必要なく、ユーザ空間へのDMAが実現できる。
- マルチコアを活用しており、フロー単位でCPUを割り当てるrun-to-completionモードと、処理単位でCPUを割り当てるpipelineモードが選択できる。
http://www.bosco-tech.com/file/160311_icm2015-muramatsu.pdf

http://blog.slankdev.net/2016/05/08/dpdk-setup/blog.slankdev.net
- vhost-user - Intel DPDKを用いて直接ユーザランドでパケット処理をする場合、vhost-netを使うとカーネルスペースとユーザスペースとのコンテキストスイッチが多く発生するため、vhost-userを用いることでコンテキストスイッチを減らすことが可能になる。
*1:例外発生時に呼ばれるコールバック関数をオーバーライトしてる?