L2転送技術まとめ+オーバーレイ
STP:スパニングツリープロトコル
- STP=802.1dは、ポートをブロックしてループフリーを実現するため、リンクを冗長化できない
- MST=802.1sは、VLANの集合ごとにスパニングツリーを作る*1ため、リンクの活用率は高くなるが、経路を冗長化することはできない
- スパニングツリーは、到達性は保証するが、最短経路を保証しない
ポートの状態遷移
- STPでは、フォワーディング状態に遷移するまでに30秒(直接リンクの障害時)または50秒(間接リンクの障害時)かかる
- RSTP=802.1wでは、エッジポート(端末が接続されているポート)の設定を行えば、転送開始するまでに1秒とかからない
Q-in-Q
- Q-in-Q=802.1adは、VLANを表すVIDを持つ802.1qヘッダを二重にすることで、VLAN範囲が4095から4095×4095まで拡張される
- ユーザのMacアドレスを全てのスイッチで学習する必要があるためスイッチへの負荷が高い
PBB:Mac-in-Mac
- PBB=802.1ahは、ユーザのEthernetフレームを、Ethernetヘッダを拡張したヘッダでカプセル化する
- PBB網内ではユーザのMacアドレスを学習する必要がないためスイッチへの負荷を抑えられる
- フルメッシュで接続するか、ループフリーを実現するなんらかのプロトコルが必要であり、冗長化を実現する手段は与えられていない
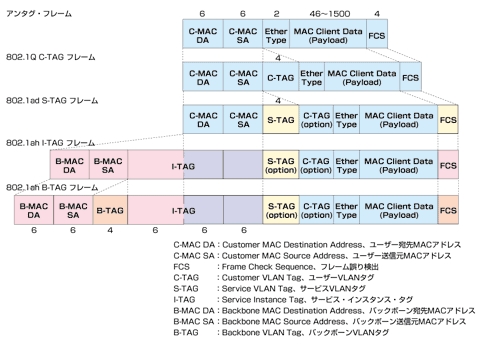
- I-TAG
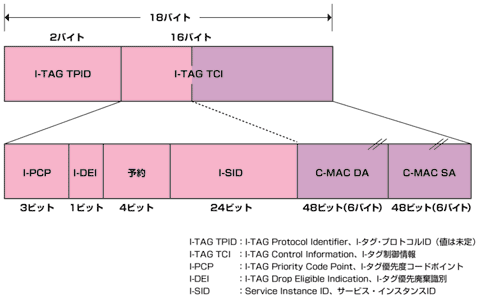
- B-TAG

[ 1/5 ] 802.1/802.3の標準化動向(6):広域イーサネット向け802.1ah PBB標準とPBB-TEの動向 | 標準化 | スマートグリッドフォーラム
SPB:Shortest Path Bridging
- MACアドレス学習は、カプセル化が解かれるスイッチ=egressスイッチで行われる
- カプセル化が施されるスイッチ=ingressスイッチにおいて、宛先MACアドレスから宛先となるegressスイッチまでの経路が決められ、その経路はVIDとして表現され、SPBヘッダが付加される際にB-TAG内のB-VDIとして設定される
- 最大で16種類の負荷分散アルゴリズム=tie-breakerが設定でき*4、VIDや宛先MACアドレスを元にして負荷分散が行われる
- SPB網内のスイッチでは、SPBヘッダのB-VDIを元に転送される
- ingressスイッチにおいて決まったツリーに従って、転送されていく
- 宛先egressスイッチまでの経路はingressスイッチで決まるため、冗長構成のループフリーなツリーを構築して、ingressスイッチで選択すればよい
- ECMPである限り、最小コストの経路しか選べないため、どのツリーもループフリーになる
- ある二つのアドレス間はどちらの方向でも同じ経路を通る
- Symmetricなパスを通ることがSPBの特徴の一つ
- ブロードキャスト・マルチキャスト・アンノウンユニキャスト、はingressスイッチで複製されるヘッドエンドレプリケーションか、SPB網内の各スイッチで複製されるタンデムレプリケーション、により転送される
TRILL:Transparent Interconnection of Lots of Links
- 経路の冗長化についてはSPBと同様
- MACアドレス学習はegressスイッチで行われる
- ingressスイッチで、宛先MACアドレスから宛先となるegressスイッチ=egress nicknameが決まり、外側イーサネットヘッダとTRILLヘッダが付加される
- TRILL網内のスイッチ=RBridgeでは、TRILLヘッダのegress nicknameを元に次ホップが決められる
- ホップバイホップで、各RBridgeにおいて次ホップを決めながら転送される
- 各RBridgeで冗長経路が考慮されるため、冗長経路を活用しやすい
- スイッチを経由するたびに外側イーサネットヘッダのアドレスが付け替えられる
- TRILLヘッダに存在するTTLによってループフリーを実現している
- ブロードキャスト・マルチキャスト・アンノウンユニキャスト、はまずツリー上のルートRBridgeに転送され、そこから全てのegress RBridgeに対して複製される
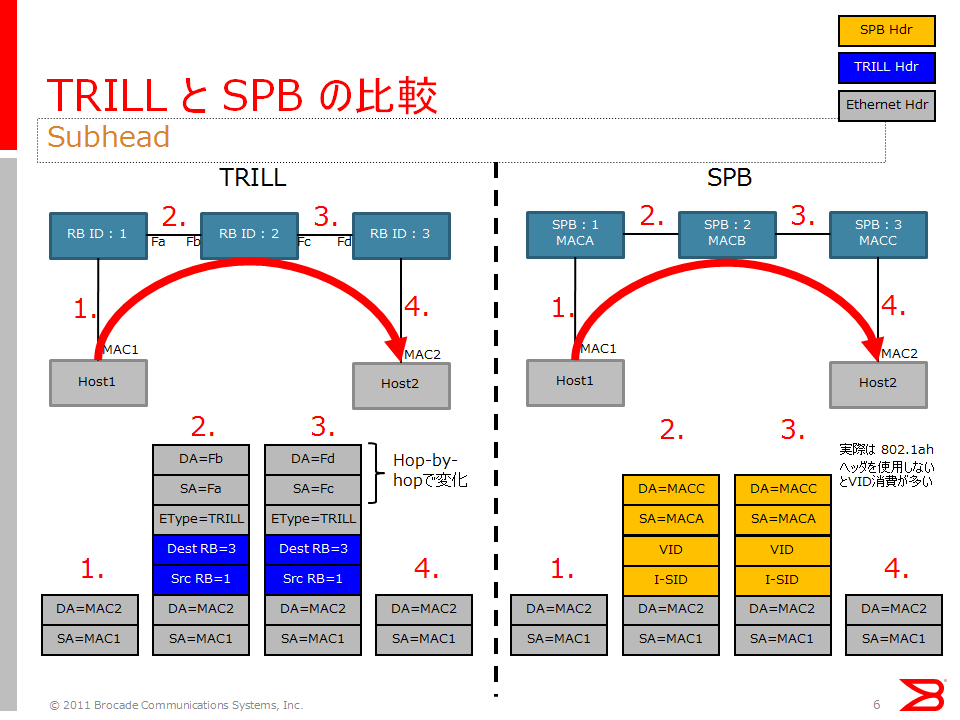
Extreme Networksの資料 http://www.trex.fi/2014/xtrm-trill-vs-spb.pdf
TRILL and IEEE 802.1aq Overview http://www.rvdp.org/publications/TRILL-SPB.pdf
日本語でのわかりやすいページ 【基礎から応用まで】Road to ネットワークスペシャリスト
オーバーレイネットワーク
- アンダーレイネットワーク(物理ネットワーク)では従来のL2/L3の技術が使える
- L2転送ではヘッダが付加されてMTUを超えてしまうとフレームが破棄されてしまうが、L3オーバーレイではIPフラグメントにより分割転送が可能
VXLAN
- オーバーレイによりL3ネットワークをまたいでL2ネットワークを形成する
- Ethernet over VXLAN+UDP
- VXLANヘッダは24ビットのVNIを持ち、これによりVLANの4095の制限を解除する
- ブロードキャスト/マルチキャスト/アンノウンユニキャストは、マルチキャストとして転送される
- VNIとIPマルチキャストグループが対応付けられていて、VNIドメインでブロードキャストされる
- 発信先のエッジVXLAN対応スイッチ(VTEP)は、受信したパケットによりVNI/MACアドレスに対する発信元VTEPの外側IPを学習し、発信元のVTEPはその応答を受信することで発信先VTEPの外側IPを学習する
- 外側ヘッダにUDPのポート番号が含まれるため、これによりVTEP間のアンダーレイに存在する汎用的な機器によって、負荷分散を行うことが可能
Aristaの資料 https://www.arista.com/assets/data/pdf/Whitepapers/Arista_Networks_VXLAN_White_Paper_jp.pdf
NVGRE
- オーバーレイによりL3を経由してL2ネットワークを形成する
- Ethernet over NVGRE+IP
- NVGREヘッダは24ビットのTNIを持ち、これによりVLANの4095の制限を解除する
NVGRE対応ハイパーバイザにARPエントリーを事前設定することでARP代理応答を行うことができ、ブロードキャストパケットが物理ネットワークに出て行かないようにすることが可能*6*7
外側ヘッダにトランスポート層のポート番号が存在しないため、汎用的な機器では負荷分散に対応できない
- 拡張NVGREヘッダでは、24ビットのVSIDと8ビットのFlow IDが定義されており、このFlow IDを識別することで負荷分散に対応できる標準が規定されている draft-chen-nvo3-load-banlancing-00 - Load balancing without packet reordering in NVO3
- VXLAN/NVGREのプロトコル処理にCPUリソースが消費されるのをできる限り回避するためHWへオフロードする
補足:不等コストロードバランス
EIGRP
- CISCO独自L3ルーティングプロトコル
- 等コストロードバランス(ECMP)に加えて、不等コストロードバランスがサポートされている
- 最短経路のコスト×variance値までのコストの経路を負荷分散対象経路として選択することが可能
- 不等コストロードバランスはループフリーを実現するための仕組みが必要になる
- EIGRPでは、最短経路の自ルータから宛先までのコスト>候補経路の隣接ルータから宛先までのコスト、という条件を加えることで候補経路に最短経路が含まれることがなくなり、ループフリーが実現できる
- なお、EIGRPのメトリックは帯域幅と遅延の両方から算出される複合メトリックであり、帯域幅は直接接続されているリンクのみ考慮するが、遅延は宛先までのパスの合計値である*8
*1:VLANの集合ごとに異なるブリッジプライオリティが設定できるため、選出されるルートブリッジが異なる
*2:基本的な動作はOSPFと良く似たプロトコルだが、OSPFのようにIPを前提とはしていない
*3:各スイッチの隣接パスのコストがマルチキャストによりフラッディングされ、ダイクストラの最短経路探索によりトポロジが決定される
*4:"By default, 16 ECTs are supported by defining 16 different ECT tie-breakers.", TRILL and IEEE 802.1aq Overview
*5:ビット誤り等はカプセル化を解いた後のスタックで行えば良く、チェックサムチェックを行わないことで少しでも処理を速くする、という想定があるのだろう
*6:"This framework allows for location information to be preconfigured inside a NVGRE endpoint allowing broadcast ARP traffic to be proxied locally.", NVGRE: Network Virtualization using Generic Routing Encapsulation, 4.1. Network Scalability with GRE
*7:ARPエントリーが事前設定されていない場合はフラッディング(おそらくマルチキャスト)されるし、事前設定が何かしらのプロトコル上で行われるのか手動設定のみになるのかは実装依存なのかもしれない
*8:この遅延の値は、リアルタイムなネットワークの状況に応じてダイナミックに変わるものではなく、事前にコンフィグされるもの